

Predictable Kubernetes costs.
Uncompromised performance.
DevZero continuously optimizes CPU and GPU allocation in Kubernetes clusters,
reducing waste and lowering costs for AI and compute workloads.



Kubernetes waste is structural, not accidental
Kubernetes optimizes for reliability, not efficiency. Datadog reports 83% of provisioned compute goes unused, creating persistent cloud waste.
Teams face an unscalable tradeoff between overprovisioning for safety and performance or manually tuning for savings.
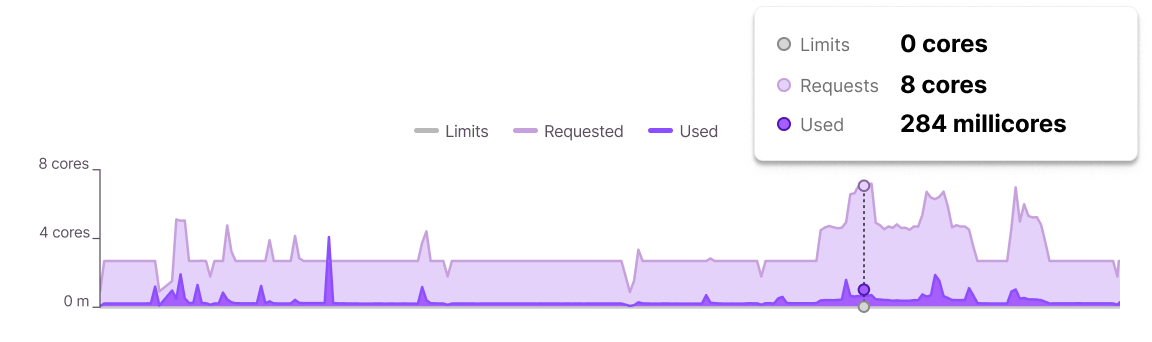
Continuous optimization, without tradeoffs
DevZero optimizes Kubernetes infrastructure in real time. The platform automatically adjusts CPU and GPU allocation as workloads change, scaling resources up during demand spikes and reclaiming waste as demand falls.
The result? Maximum efficiency without compromising performance. No manual tuning, scheduled guesswork required.
“We started applying DevZero’s recommendations on day 5, and within 24 hours our daily spend dropped by 30%. By day 30, we hit 60% total savings. That’s faster ROI than any other infrastructure investment we’ve made.”
Why DevZero
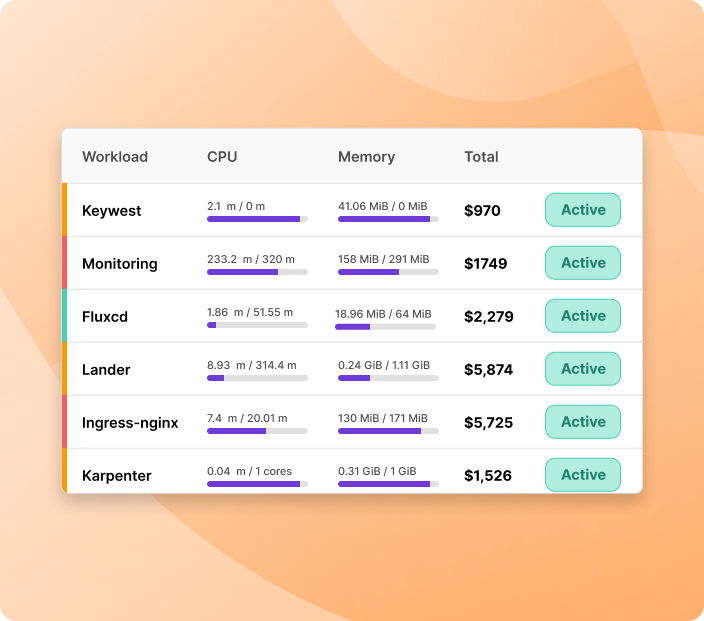
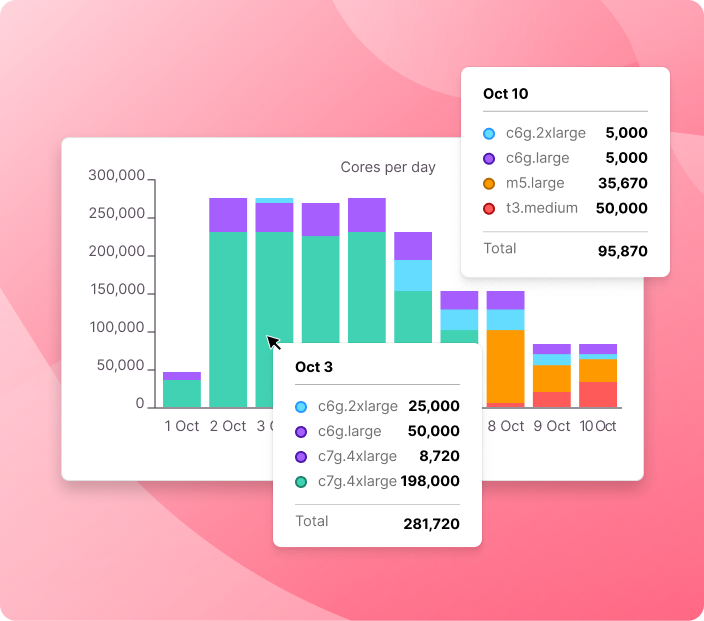
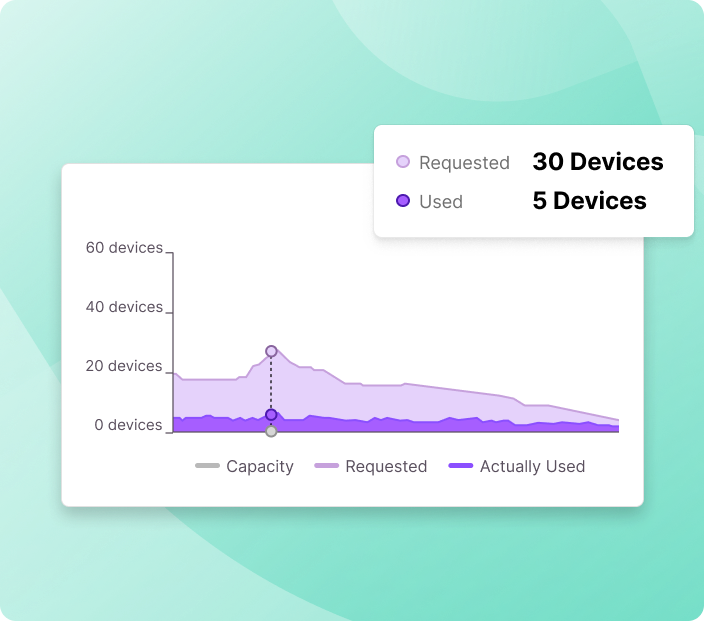
Use Cases
Symptoms: Low GPU Streaming Multiprocessor utilization, small batches occupying entire GPUs, oversized KV caches and default sequence lengths, and idle replicas kept warm to avoid cold starts.
Why there’s waste: Conservative batching and CPU-bound preprocessing lead to GPU starvation. Fragmentation across GPU types reduces packing efficiency, while always-on replicas consume expensive GPU hours without active workloads.
How to fix it: Implement smarter batching and queue-based autoscaling to maximize GPU throughput. Use fractional GPU sharing (e.g., MIG) for smaller workloads, and group deployments by GPU type to improve bin-packing and reduce waste.
DevZero provides Kubernetes‑native Platform with zero‑downtime live migration and a Multi‑dimensional Pod Autoscaler (MPA) that adjusts replicas, CPU, and memory in place based on real usage. It dynamically selects optimal instance types, improves bin‑packing, and releases unused memory via sandbox RAM resizing—delivering higher node utilization and lower cost without restarts or app changes. For AI workloads, DevZero supports GPU multi‑tenancy (e.g., MIG) to raise utilization safely. The platform surfaces savings insights and automates recommendations through lightweight operators, enabling live rightsizing across clusters, namespaces, and workloads.
Symptoms: Traffic arrives in short, random bursts. Autoscalers frequently overshoot or undershoot, causing replicas to oscillate. The result: low average utilization punctuated by sudden saturation, queue spikes, and tail-latency blowups.
Why there’s waste: Conservative static requests and HPA/VPA thresholds keep excess headroom “just in case.” Slow scale-down timers waste warm capacity. Reliance on CPU-only metrics misses true saturation drivers like queue depth or latency.
How to fix it: Adopt smarter, signal-rich autoscaling. Use queue or latency-based scaling with faster cooldowns. Combine burst buffers (scale-to-zero + rapid spin-up) with adaptive rightsizing to p95/p99 patterns. Leverage event-driven scaling (e.g., KEDA) tied to queue depth or throughput. Minimize minimum replicas and choose smaller pod shapes for finer-grained control.
DevZero provides Kubernetes‑native Platform with zero‑downtime live migration and a Multi‑dimensional Pod Autoscaler (MPA) that adjusts replicas, CPU, and memory in place based on real usage. It dynamically selects optimal instance types, improves bin‑packing, and releases unused memory via sandbox RAM resizing—delivering higher node utilization and lower cost without restarts or app changes. For AI workloads, DevZero supports GPU multi‑tenancy (e.g., MIG) to raise utilization safely. The platform surfaces savings insights and automates recommendations through lightweight operators, enabling live rightsizing across clusters, namespaces, and workloads.
Symptoms: Large nodes are provisioned for short ETL windows, then left running after jobs complete. Memory and I/O utilization are inconsistent, with lingering half-used resources, orphaned PVCs, and stale snapshots.
Why there’s waste: Windowed workloads over-reserve capacity for brief bursts. Inefficient teardown and retention policies keep unused resources alive, while mismatched pod shapes reduce bin-packing efficiency.
How to fix it: Use spot or preemptible instances with checkpoint/restore to cut idle time and cost. Standardize pod shapes to improve bin-packing and automate teardown after workload completion.
DevZero provides Kubernetes‑native Platform with zero‑downtime live migration and a Multi‑dimensional Pod Autoscaler (MPA) that adjusts replicas, CPU, and memory in place based on real usage. It dynamically selects optimal instance types, improves bin‑packing, and releases unused memory via sandbox RAM resizing—delivering higher node utilization and lower cost without restarts or app changes. For AI workloads, DevZero supports GPU multi‑tenancy (e.g., MIG) to raise utilization safely. The platform surfaces savings insights and automates recommendations through lightweight operators, enabling live rightsizing across clusters, namespaces, and workloads.
Symptoms: Periodic workloads such as reports, backups, and feature engineering create short bursts of activity followed by long idle periods. Nodes often remain unused, and conservative resource limits are set to “avoid failures.”
Why there’s waste: Resources are statically sized for peak demand instead of typical usage. Autoscaling is not connected to real workload signals like queue depth or runtime metrics, leading to consistent overprovisioning.
How to fix it: Use dynamic rightsizing based on observed utilization. Scale to zero between runs to remove idle costs, and expand spot instance diversity to handle bursts more efficiently.
DevZero provides Kubernetes‑native Platform with zero‑downtime live migration and a Multi‑dimensional Pod Autoscaler (MPA) that adjusts replicas, CPU, and memory in place based on real usage. It dynamically selects optimal instance types, improves bin‑packing, and releases unused memory via sandbox RAM resizing—delivering higher node utilization and lower cost without restarts or app changes. For AI workloads, DevZero supports GPU multi‑tenancy (e.g., MIG) to raise utilization safely. The platform surfaces savings insights and automates recommendations through lightweight operators, enabling live rightsizing across clusters, namespaces, and workloads.
Symptoms: Some clusters operate below 30% utilization while others run at or near capacity. Each cluster carries fixed overhead from add-ons like service mesh, logging, and security agents, regardless of load. Capacity remains stranded due to strict isolation.
Why there’s waste: Single-tenant isolation prevents consolidation and leads to uneven utilization. Inconsistent workload shapes make efficient binpacking difficult, and baseline overhead multiplies across clusters.
How to fix it: Consolidate tenants where compliance allows. Standardize pod shapes for better packing efficiency, right-size add-ons to match actual usage, and implement showback or chargeback to highlight underused clusters and encourage migration.
DevZero provides Kubernetes‑native Platform with zero‑downtime live migration and a Multi‑dimensional Pod Autoscaler (MPA) that adjusts replicas, CPU, and memory in place based on real usage. It dynamically selects optimal instance types, improves bin‑packing, and releases unused memory via sandbox RAM resizing—delivering higher node utilization and lower cost without restarts or app changes. For AI workloads, DevZero supports GPU multi‑tenancy (e.g., MIG) to raise utilization safely. The platform surfaces savings insights and automates recommendations through lightweight operators, enabling live rightsizing across clusters, namespaces, and workloads.
Symptoms: Preview and staging environments stay live long after pull requests are merged, including overnight and on weekends. These clusters show low CPU utilization but high memory reservations, with orphaned load balancers, PVCs, and images. Autoscaling is often disabled for “reproducibility.”
Why there’s waste: Convenience and caution take priority over cleanup. There are no TTL policies, inactivity detection, or scheduled shutdowns. Generous default resource settings, such as 1 vCPU and 2–4 GB of memory per service, keep nodes pinned even when there is no traffic.
How to fix it: Enable automatic teardown when pull requests are merged or closed. Add inactivity timers to hibernate or scale to zero unused environments. Schedule off-hours shutdowns with morning resumes, use snapshot and restore for databases, and right-size resources based on p95 usage.
DevZero provides Kubernetes‑native Platform with zero‑downtime live migration and a Multi‑dimensional Pod Autoscaler (MPA) that adjusts replicas, CPU, and memory in place based on real usage. It dynamically selects optimal instance types, improves bin‑packing, and releases unused memory via sandbox RAM resizing—delivering higher node utilization and lower cost without restarts or app changes. For AI workloads, DevZero supports GPU multi‑tenancy (e.g., MIG) to raise utilization safely. The platform surfaces savings insights and automates recommendations through lightweight operators, enabling live rightsizing across clusters, namespaces, and workloads.
Cluster Optimization vs. Workload Optimization
Autoscalers like Karpenter and KEDA focus on scaling down (and up) idle nodes. That means that a node with one small workload would not scale down.
DevZero is focused on optimizing workloads and optimizing their requirements for compute and memory and binpacking workloads, moving them from underutlized nodes to better optimized nodes, which is where majority of the waste is.

Free Kubernetes Assessment
Get a free self-serve assessment of your Kubernetes cluster - visualize costs by nodes, node groups and workloads. See which workloads are more expensive (and overprovisioned) and how much you can save.